
Archiwistyka Webu na UW
-
- Archiwistyka Webu
-
- Redakcja Humanistyka Cyfrowa na UW
- 12.03.2024
-
- Artykuł
Powstała na przełomie lat 80. i 90. sieć World Wide Web (WWW) jest dziś kluczową usługą internetu. Chociaż historycznie młodsza od innych usług sieciowych takich jak poczta elektroniczna czy IRC (Internet Relay Chat), zdominowała nasze myślenie o internecie. Współcześnie WWW nie tylko umożliwia użytkownikom i użytkowniczkom dostęp do ogromnej ilości informacji i zasobów publikowanych na stronach internetowych, ale też pozwala na oferowanie rozmaitych usług online – od bankowości internetowej, przez systemy nawigacyjne, po przeglądarkowe gry online.
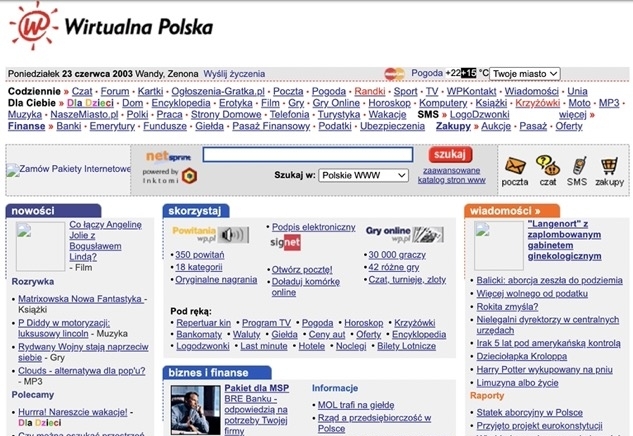
Witryna „Wirtualna Polska” z 23.06.2003 r. zarchiwizowana w Internet Archive, dostępna przez Wayback Machine.
Treści publikowane za pomocą WWW już w połowie lat 90. znalazły się w polu zainteresowania historyków i archiwistów. Założyciel fundacji Internet Archive – Brewster Khale – już w 1996 roku zainicjował program archiwizowania części zasobów Webu, traktując je jako dziedzictwo historyczne i potencjalne źródła w przyszłych badaniach historycznych. Dziś archiwizacja Webu jest obowiązkiem wielu bibliotek i archiwów narodowych na świecie, a badacze i badaczki sięgają po te zbiory przy opracowywaniu tematów z historii najnowszej. Archiwa Webu przydatne są także w pracy dziennikarskiej i działaniach organizacji pozarządowych, szczególnie tych specjalizujących się w walce z dezinformacją online lub ochroną zagrożonego dziedzictwa cyfrowego (przykład: Saving Ukrainian Cultural Heritage Online).
Można wyróżnić dwa podejścia do archiwistyki Webu – mówi Marcin Wilkowski, historyk, programista i specjalista od historii internetu w CKC UW. – W pierwszym WWW jest po prostu dziedzictwem kulturowym, więc archiwistyka Webu to metody pozwalające na eksplorację tego dziedzictwa i jego zabezpieczanie na bieżąco. W drugim WWW to przestrzeń poddawana analizie – czy to w ramach projektów naukowych czy akcji dziennikarskich, a nawet białego wywiadu. Tutaj główny akcent kładzie się na zabezpieczanie publikowanych online informacji oraz docieranie do nich w archiwach Webu. Częścią tego podejścia jest też praca na rzecz stabilności zasobów online wykorzystywanych w pracach naukowych – na przykład linkowanych w przypisach. Archiwistyka Webu to szeroka gama metod i narzędzi, którą wykorzystać można w naprawdę różnych celach – od nostalgicznego przeglądania starych witryn po pracę dokumentacyjną czy wspieranie komunikacji naukowej.

Struktura pliku WARC (Web ARChive) (źródło: T. Preece, Web Archiving: Formats)
W Centrum Kompetencji Cyfrowych UW działa Pracownia Archiwistyki Webu (webArch). To jedna z trzech pracowni rozwijanych w CKC w ramach Działania I.3.6. „Humanistyka cyfrowa” w Programie IDUB. Jej celem jest gromadzenie i upowszechnianie wiedzy na temat podstaw budowania archiwów Webu i pracy z nimi. Jako jedyna taka inicjatywa w Polsce oferuje także warsztaty i szkolenia, a od niedawna publikuje newsletter naukowy.
Na stronach pracowni dostępne są podstawowe opracowania na temat archiwistyki Webu (POD TYM LINKIEM). Dobrym wstępem do tej dziedziny jest podręcznik „Wykorzystanie archiwów Webu w badaniach” (do pobrania POD TYM LINKIEM), będący rozwinięciem publikacji J. Nielsen z 2016 roku.
Tekst pierwotnie opublikowany został w portalu Humanistyka Cyfrowa na UW.